A New Electronic Dashboard For Parliamentary Bills
Two hours, forty-six minutes. That's how long it took two bored developers to turn the UK Parliament's data feed into something which doesn't suck. Today the Restorationist™ releases the first vomit draft of its bill browsing app, to anyone, free and open source. You may not like the content.


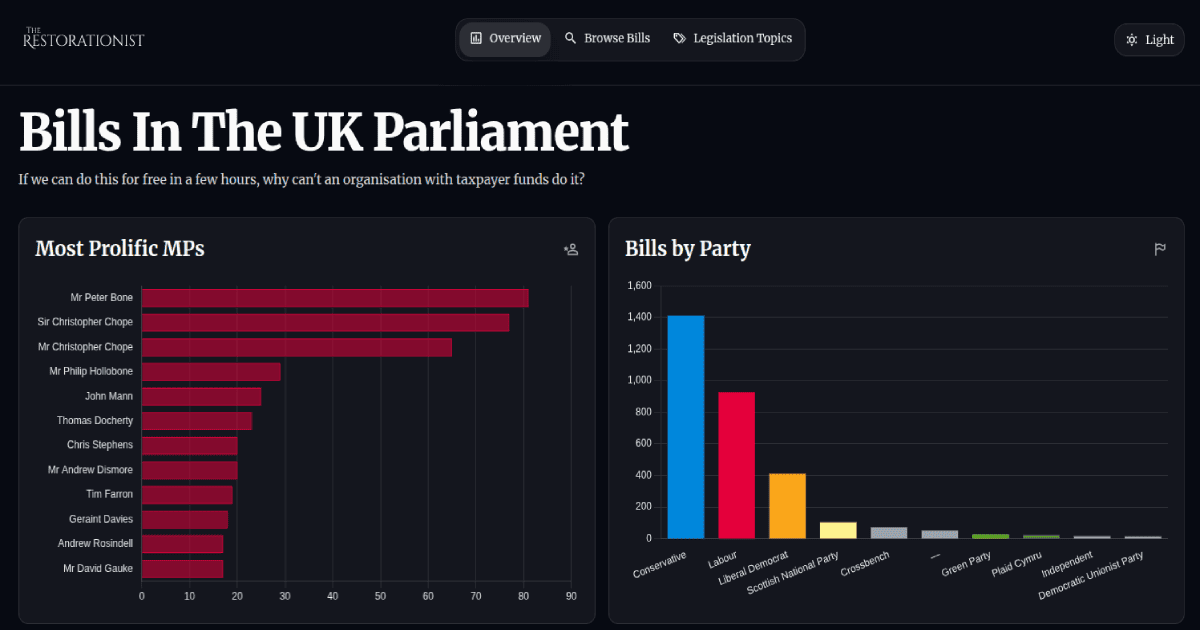
It's incredible how few people know every useless bill submitted to Parliament is published openly for anyone to read. It's less surprising anyone knows Parliament has its own developer portal, where it publishes its APIs. It may like look like fashionable garbage from 2003; it may not respond in less than 3000ms; and it may not do what it says. But it has Swagger/OpenAPI definitions, and whichever intern hacked this together on a Tuesday deserves some credit. Most likely it was a Euro-agency paid £30 million by the Civil Service so they could hire 15,000 new staff as project managers. It could have been worse. It's surprising they didn't provide it as SOAP.
Restorationists get rather irked when they don't have anything to restore for a few hours, and we're no exception. So after a brief Slack argument, the challenge was there – it's an API, so let's see how long it takes to create something usable which looks like it was created after 2010.
How This Thing Works
Go to https://bills.restorationist.org.uk/. You see a pretty finalised site. That's it. But if you're a dev, you'll be curious how it was put together. Read on.
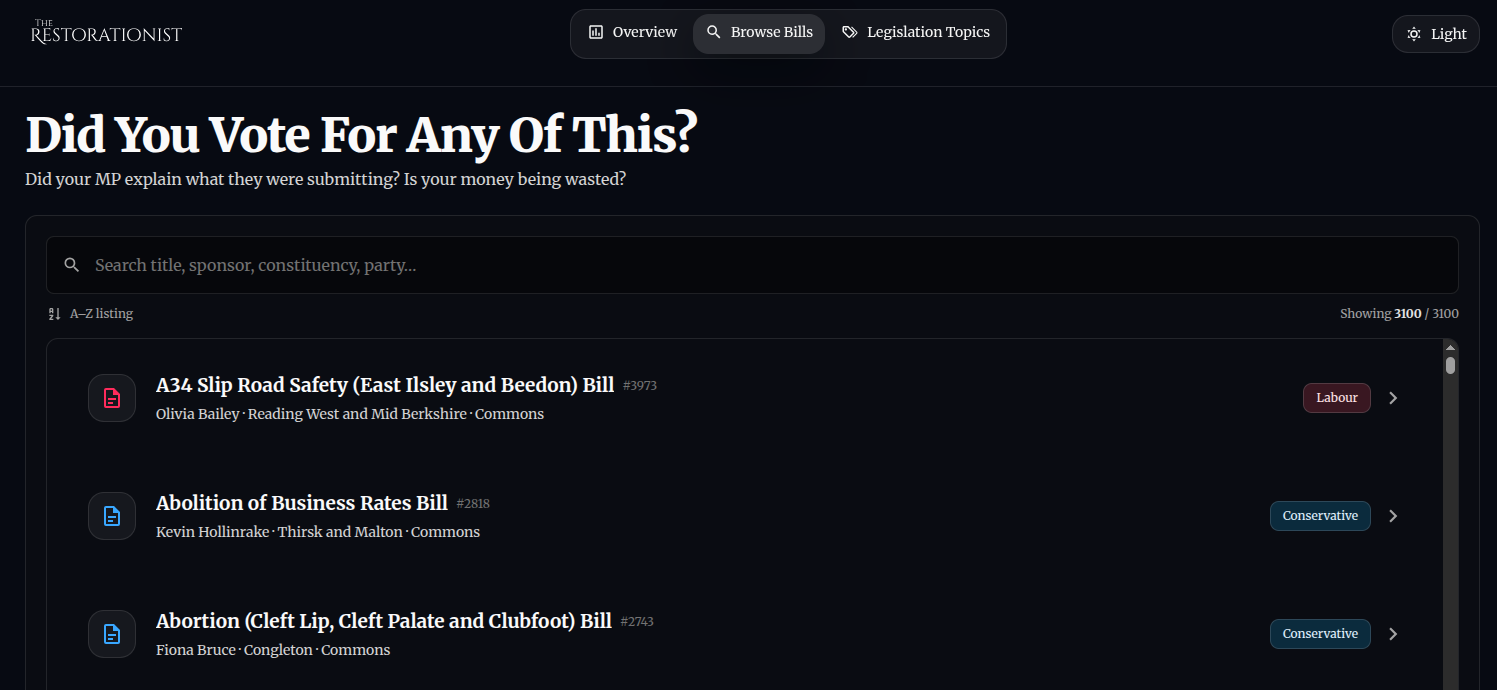
- Downloading all the bill data by iterating the paginated results from the Bills API.
- Strip the members (idiots) out of it to get a reference list of clowns.
- Cut down the garbage and produce a simplified list of bills and their "purposes" which is usable.
- Parse the same bill data for patterns and stats.
By then, you should have six files:
Cup of tea or coffee, and maybe a cigarette. The worst is over.
Next, feed your bills_simplified.csv into your favourite LLM with a prompt to classify the 4000 garbage items from said clowns into topic groups, to find out what horseshit they are attempting to legislate.
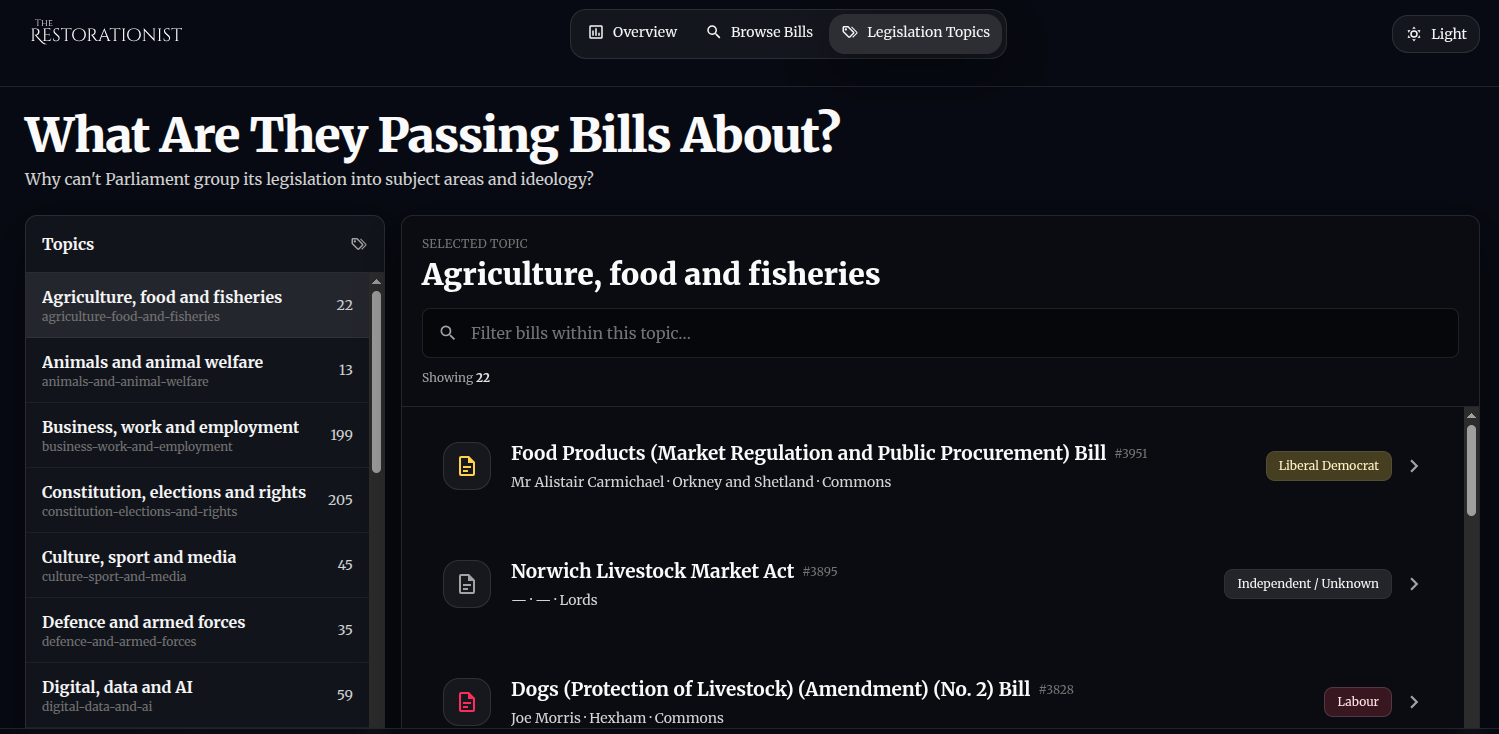
This data does change too regularly, so you really don't need to keep much of it live. A scheduled cache update, build, and publish, is enough.
Final step? Make it dark mode. Because the old Bootstrap donkey crap they are using at the Civil Service is a decade out of date.
- Tailwind CSS
- Svelte - this is a BRITISH framework
- ChartJS
- Vite
No database. Just query the JSON, and lazy-load it intelligently because it's large.
That's it. Two hours , forty-six minutes later, you have dark mode dashboard. Browse the code yourself, download, and remix.
Making It Into Something Good
This site uses static data (JSON files), so the obvious next step is to add a backend process to download, sort, and cache updates to Parliament's API data. That's trivial – if the API works. Live data is far more useful.

- A basic Python serverless lambda function to query the API every 4hrs and resolve changes into the cache, rather than deal with the hopelessly slow mess published now.
- Storage of bill, member, and publication data in Elasticsearch, for natural language processing, providing more in-depth linguistics and vector embeddings for RAG. Yes, you could use Weaviate or ChromaDB, but you'd lose the NLP search goodness.
- Downloading publication attachments (PDFs, HTML) and stripping them for raw text with Apache Tika next to the bill data.
- Sending the raw text to different LLMs for summarisation and analysis, such as Groq or OpenRouter.
None of this will make the bills any better, but they'll be a lot faster to parse through and at least it'll be dark mode.